· International Trade · 4 min read
파이썬을 이용한 경제 데이터 분석 예
FRED API 데이터 스크레이핑을 이용한 차트 분석
FRED API 데이터 스크레이핑을 이용한 차트 분석
경제학에서 컴퓨터를 주로 이용하는 전공 분야는 보통 통계기법을 주로 이용하는 계량경제학과 컴퓨터를 이용해 모형을 분석하는 전산경제학(Computational Economics)가 있다. 지금까지 이쪽 전공자들은 주로 STATA, R, Matlab, Maple 등의 소프트웨어를 이용해 왔다. 그러나 최근 들어 파이썬(Python) 사용자들이 점점 늘어나며 관심을 끌고 있다. 사실 파이썬은 현재 데이터과학은 물론 인공지능, 머신러닝 등 많은 분야에서 주로 사용하는 도구이며 더 많은 이용자들이 자유롭게 사용하며 그 유용성도 점점 높아지고 있다.
여기서는 몇 가지 계량경제학 부문에서 사용하는 코딩 예를 소개해 본다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly.express as px
import time
plt.style.use('fivethirtyeight')
pd.options.display.max_columns=500
color_pal = plt.rcParams["axes.prop_cycle"].by_key()["color"]
from fredapi import Fred
fred_key = 'FRED-API key를 입력해 주세요.'
fred = Fred(api_key=fred_key)FRED API를 이용하기 위해서는 사용자 등록과 함께 API-key 신청하면 무료로 API를 이용할 수 있다.
S & P 500 주가 지수 시계열
sp_search = fred.search('S&P', order_by='popularity')
sp500 = fred.get_series(series_id='SP500')
sp500.plot(figsize=(10, 5), title='S&P 500', lw=2)
plt.show()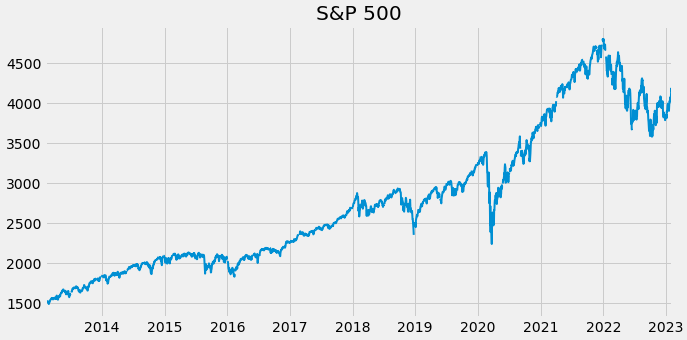
미국 각 주별 실업률 비교 분석
unemp_df = fred.search('unemployment rate state', filter=('frequency','Monthly'))
unemp_df = unemp_df.query('seasonal_adjustment == "Seasonally Adjusted" and units == "Percent"')
unemp_df = unemp_df.loc[unemp_df['title'].str.contains('Unemployment Rate')]
all_results = []
for myid in unemp_df.index:
results = fred.get_series(myid)
results = results.to_frame(name=myid)
all_results.append(results)
time.sleep(0.1) # Don't request to fast and get blocked
uemp_results = pd.concat(all_results, axis=1)
cols_to_drop = []
for i in uemp_results:
if len(i) > 4:
cols_to_drop.append(i)
uemp_results = uemp_results.drop(columns = cols_to_drop, axis=1)
uemp_states = uemp_results.copy() #.drop('UNRATE', axis=1)
uemp_states = uemp_states.dropna()
id_to_state = unemp_df['title'].str.replace('Unemployment Rate in ','').to_dict()
uemp_states.columns = [id_to_state[c] for c in uemp_states.columns]
# Plot States Unemployment Rate
px.line(uemp_states)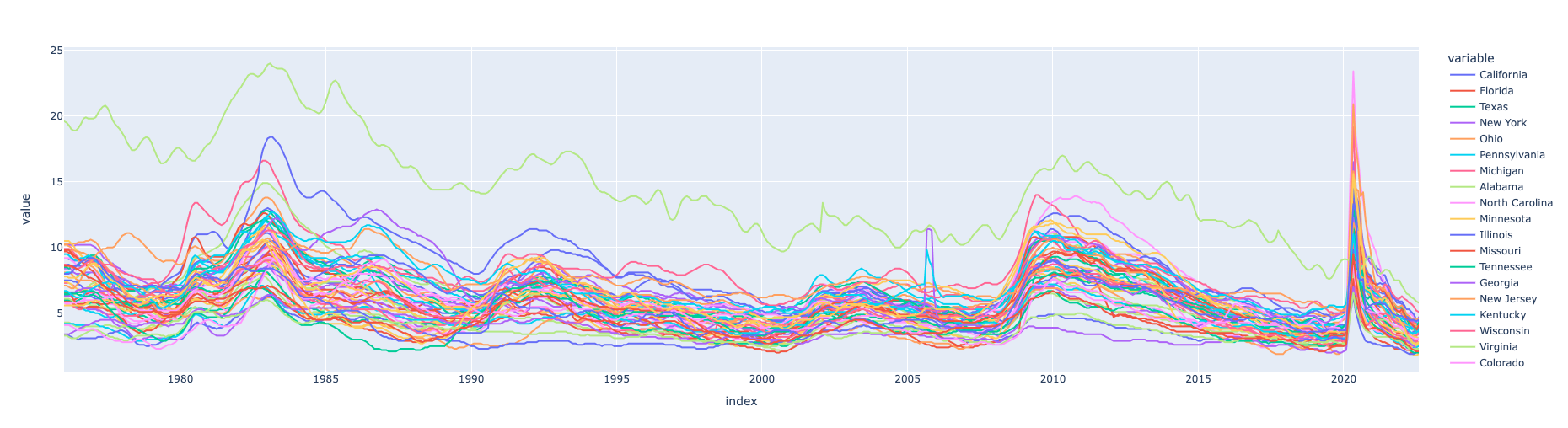
ax = uemp_states.loc[uemp_states.index == '2020-05-01'].T \
.sort_values('2020-05-01') \
.plot(kind='barh', figsize=(8, 12), width=0.7, edgecolor='black',
title='Unemployment Rate by State, May 2020')
ax.legend().remove()
ax.set_xlabel('% Unemployed')
plt.show()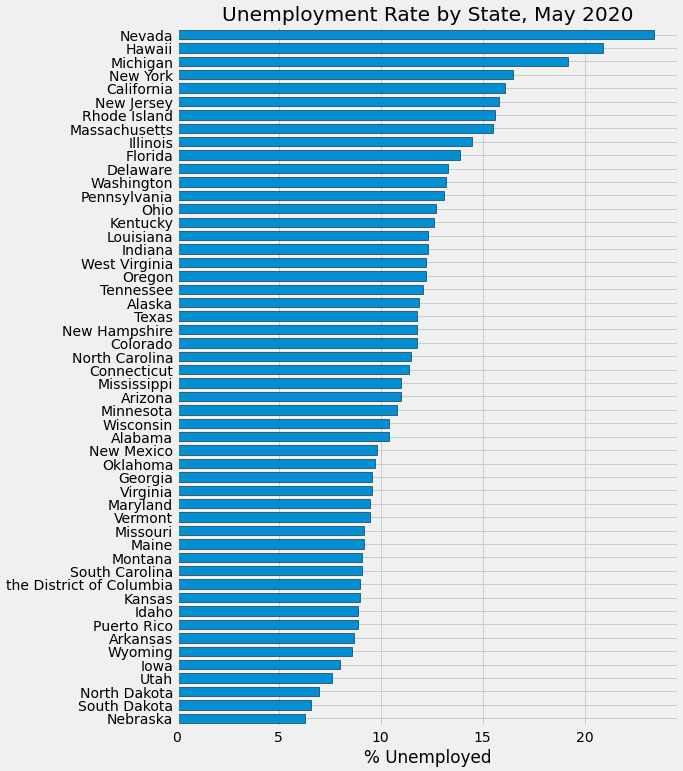
실업률 대비 경제활동참가율 동향 분석
실업률과 경제활동참가율에 대한 정확한 공식을 정리해 본다.
실업률(%) 경제활동참가율(%) 경제활동인구는 취업자와 실업자의 총합이며, 노동가능인구는 15세 이상 인구 총합을 의미한다.
part_df = fred.search('participation rate state', filter=('frequency','Monthly'))
part_df = part_df.query('seasonal_adjustment == "Seasonally Adjusted" and units == "Percent"')
part_id_to_state = part_df['title'].str.replace('Labor Force Participation Rate for ','').to_dict()
all_results = []
for myid in part_df.index:
results = fred.get_series(myid)
results = results.to_frame(name=myid)
all_results.append(results)
time.sleep(0.1) # Don't request to fast and get blocked
part_states = pd.concat(all_results, axis=1)
part_states.columns = [part_id_to_state[c] for c in part_states.columns]
# Fix DC
uemp_states = uemp_states.rename(columns={'the District of Columbia':'District Of Columbia'})
fig, axs = plt.subplots(10, 5, figsize=(30, 30), sharex=True)
axs = axs.flatten()
i = 0
for state in uemp_states.columns:
if state in ["District Of Columbia","Puerto Rico"]:
continue
ax2 = axs[i].twinx()
uemp_states.query('index >= 2020 and index < 2022')[state] \
.plot(ax=axs[i], label='Unemployment')
part_states.query('index >= 2020 and index < 2022')[state] \
.plot(ax=ax2, label='Participation', color=color_pal[1])
ax2.grid(False)
axs[i].set_title(state)
i += 1
plt.tight_layout()
plt.show()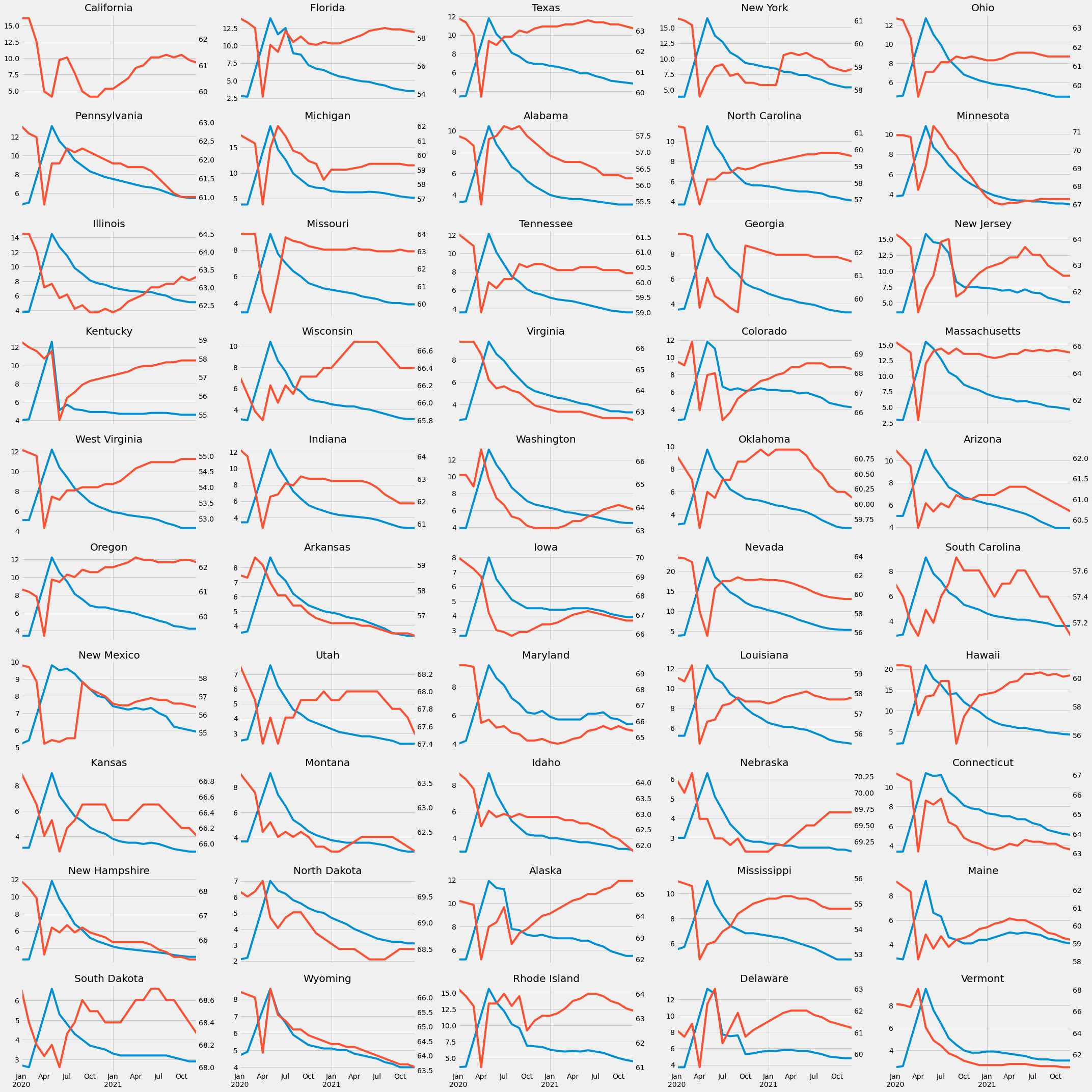
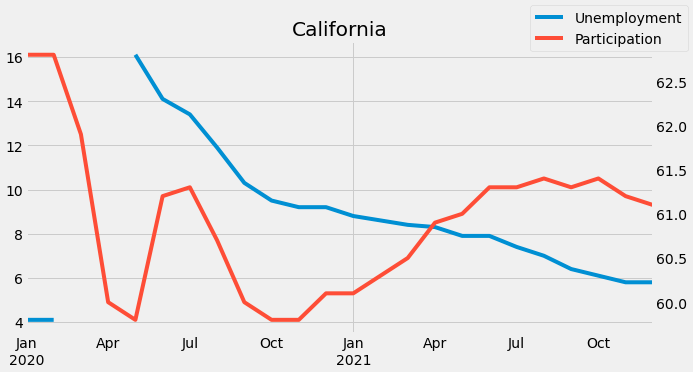
주별 실업률 대비 경제활동참가율 개별 분석예: 캘리포니아
state = 'California'
fig, ax = plt.subplots(figsize=(10, 5), sharex=True)
ax2 = ax.twinx()
uemp_states2 = uemp_states.asfreq('MS')
l1 = uemp_states2.query('index >= 2020 and index < 2022')[state] \
.plot(ax=ax, label='Unemployment')
l2 = part_states.dropna().query('index >= 2020 and index < 2022')[state] \
.plot(ax=ax2, label='Participation', color=color_pal[1])
ax2.grid(False)
ax.set_title(state)
fig.legend(labels=['Unemployment','Participation'])
plt.show()